저번 글에서는 R script에 대해 알아보았다 (아래 링크 참고).
R studio 공간: 1. R Script
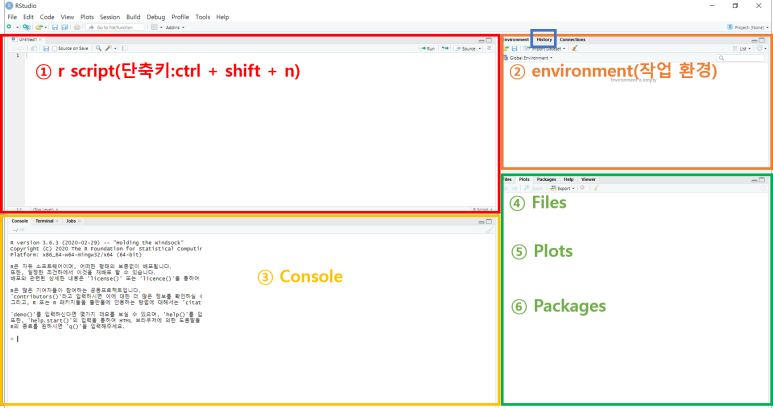
R Studio 공간 R과 R Studio를 설치했다면, 이제 R Studio의 공간을 살펴보자 R studio는 아래의 그림과 같이 크게 4가지 공간으로 분할되어 있다. 처음 다운로드해서 켜신 분이라면, 왼쪽에 빨간색 공간(sc
psstat.tistory.com
이번 글에서는 아래의 공간들 중 environment를 다룰 것이다.
이를 알아보기 전 객체(object)라는 개념을 간단하게 다루는 것이 좋을 듯하다.
객체는 간단하게 어떤 값들을 담는 그릇이라 생각할 수 있다.
그릇에 여러 종류의 과일이나 음식 혹은 물건들을 보관하는 것처럼,
객체에 여러 종류의 값들을 담아두고 우리의 필요에 맞게 값들을 가공하여 사용할 수 있다.
객체의 이름은 사용자가 원하는 것으로 사용하면 된다.
예를 들어, 2라는 숫자를 담은 객체를 생성해보자. 이 때 객체의 이름은 x라고 할 것이다.
이러한 객체는 'x <- 2'라는 코드를 입력하면 만들어진다.
이와 같이 화살표(<-)를 받는 쪽(즉, 위의 예에서는 화살표의 왼쪽)은 객체 이름에 해당하고,
화살표를 주는 쪽은 객체에 저장할 값들이 입력된다고 생각하시면 되겠다.
만약 객체 이름을 y로 하고 싶다면 'y <- 2'라는 코드를 사용하면 될 것이다.
객체에 관한 내용은 나중에 다룰테니 이 정도로 하고 environment에 대해 알아보자.
1. 값(values)
기본적으로 environment 창에서는 내가 지정한 값에 대한 대략적 정보들을 확인할 수 있다.
먼저 아래의 코드들을 실행해서 3개의 객체를 만들어보자.
#generate value
subject <- c(1,1,1,2,2,2,3,3,3)
condition <- c(1,2,3,1,2,3,1,2,3)
recall <- c(9,8,6,8,10,4,6,5,7)위의 코드를 입력하면 각 9개의 값들을 가진 subject, condition, recall이라는 이름의 세 가지 객체가 생성된다.
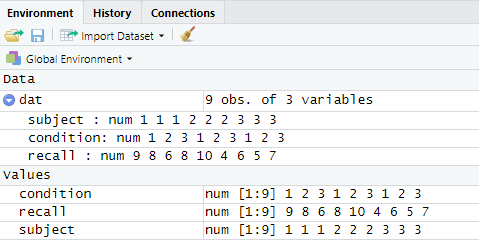
이렇게 객체를 생성한 뒤 environment 창을 보면, 생성된 객체와 각 객체의 대략적 정보를 확인할 수 있다.
예를 들어, 아래 스크린샷에 'num'이라고 적혀있는데 이는 객체에 저장된 값의 자료 형태를 말해준다.
'num'은 numeric의 약자로 세 객체의 자료 형태가 모두 숫자형임을 알 수 있다.

2. 데이터 세트
environment 창에서는 여러 값들을 지닌 변수들로 이루어진 데이터 세트에 대한 정보도 확인할 수 있다.
아래의 코드를 이용해서 위에서 생성한 객체들로 구성된 데이터 세트를 만들 수 있다.
#generate dataframe
dat <- data.frame(subject, condition, recall)위의 코드를 실행하고 'dat'을 실행하면, 우리가 의도한 대로 데이터 세트가 만들어진 것을 확인할 수 있다.

이제 다시 environment 창으로 넘어가면,
아래의 스크린 샷과 같이 'dat'라는 이름의 데이터 세트가 만들어진 것을 확인할 수 있다.
1번에서와 마찬가지로, environment 창에서 'dat'이라는 데이터 세트의 대략적 정보를 확인할 수 있다.
9 obs. of 3 variables라고 되어 있는데,
이는 'dat'이라는 데이터 세트가 9개의 관찰치를 지닌 3개의 변인으로 구성되어 있음을 의미한다.
또 dat이라는 이름 앞에 파란색 바탕의 흰색 화살표가 있는데, 이걸 누르면 아래 그림과 같이
이 데이터 세트를 구성하는 열(column)의 이름과 각 열의 값들이 갖는 관찰치의 자료 유형을 보여준다.
*참고로 environment 창에서 확인할 수 있는 데이터 세트의 정보들은 다음의 코드를 사용하여 확인할 수도 있다.
#check structure
str(dat)위의 코드를 실행하면, 아래 스크린샷과 같은 화면이 나타날텐데,
이는 environment 창에서 확인한 것과 동일하다.

위의 코드에서 str은 structure의 약자로, 해당 함수는 객체 구조를 아주 간략하게 보여주는 함수이다.
이를 통해 우리는 environment 창이 객체가 어떤 구조를 지니는지 보여준다는 것을 알 수 있다.
3. 분석 모형
environment 창에서는 값이나 데이터 세트에 관한 객체뿐 아니라
분석 모형을 담고있는 객체도 확인할 수 있다.
무슨 말인지 아래의 anova분석 예시로 살펴보자.
(anova분석이 무엇인지는 따로 설명하지 않을텐데,
독립변인이 범주형이고 종속변인이 연속형일 때 집단 간 차이를 알아보는 목적으로 사용되는 통계기법이라는 정도로만 이해하자)
#change data type of condition from numeric to factor
dat$condition <- as.factor(dat$condition)
#analyze
result <- aov(recall ~ condition, data = dat)위의 코드를 잠깐 살피면 먼저
우리가 생성한 값들 중에서 condition에 속하는 값의 자료 유형을 연속형에서 범주형으로 변환해 주었다.
as.factor(dat$condition)은 dat이라는 데이터 세트 중에서 condition의 값들을 요인 형태로 변환하라는 말이다.
그 후, aov()함수를 사용한 anova 분석모형을 'result'라는 이름의 객체에 담았다.
여기까지 코드를 실행시키고 다시 environment 창을 보면, 아래의 스크린샷과 같은 화면이 나타날 것이다.

여기서 일단 우리가 요구한 대로 'dat' 데이터 세트 내의 condition 값들이 "1", "2", "3"이라는
세 수준을 갖는 요인으로 변환된 것을 확인할 수 있다.
그리고 anova 분석 모형이 담긴 result라는 객체가 생성된 것을 확인할 수 있다.
여기서 list는 r의 데이터 형태 중 하나인데, 데이터 형태는 아직 다루지 않았으므로 이런 게 있구나 정도로만 알고 넘어가시면 좋겠다.
**마무리
개인적으로는 객체를 많이 안 만들면 environment 창을 자주 활용하지는 않는다.
그런데 raw데이터에 전처리를 하면서 새로운 객체가 만들어지고, 만들어지고, 또 만들어지는 경우들이 있는데, 이 때 내가 어떤 객체 이름들을 사용하였는지 헷갈리는 경우들이 있다.
만약 x라는 객체 이름을 내가 이미 사용했는데, 그것을 깜빡하고 x라는 객체 이름에 새로운 값들을 할당하면
이전에 부여한 값들은 없어진다. 일종의 덮어쓰기가 되는 셈이다.
따라서 여러 객체를 만들 때, environment 창에서 내가 어떤 객체 이름들을 사용하였는지 확인하면 위와 같은 실수를 줄일 수 있을 것이다.
어쨌든 이처럼 environment창은 내가 어떤 객체를 생성했는지 확인하거나
데이터 세트의 간략한 정보들을 확인할 때 사용할 수 있다.
'R studio > R studio 설치 및 공간 탐색' 카테고리의 다른 글
| [R studio]Working directory(작업 공간) 설정 (0) | 2021.09.26 |
|---|---|
| R studio 작업환경 설정: 인코딩 변경, 자동 줄 바꿈, 커서 라인 하이라이트 (1) | 2020.10.02 |
| R studio 공간 살펴보기: 3. Console, 4. Files, 5. Plots, 6. Packages (0) | 2020.09.03 |
| R studio 공간: 1. R Script (0) | 2020.08.28 |
| R studio 설치 (0) | 2020.08.23 |